
Summary
| Full name | 5' nicotinamide adenine dinucleotide |
| Short name | NADpN |
| MODOMICS code new | 2000000255N |
| MODOMICS code | 255N |
| Nature of the modified residue | Natural |
| RNAMods code | Ξ |
| Residue unique ID | 154 |
| Found in RNA | Yes |
Chemical information
| Sum formula | C26H33N7O20P3 |
| Type of moiety | nucleotide |
| Degeneracy | unspecified residue |
| SMILES | NC(c1ccc[n+]([C@@H]2O[C@H](COP([O-])(OP([O-])(OC[C@H]3O[C@@H]([n]4cnc5c(N)ncnc45)[C@H](O)[C@@H]3OP([O-])(OC[C@H]3O[C@@H]%91[C@H](O)[C@@H]3O)=O)=O)=O)[C@@H](O)[C@H]2O)c1)=O.[*]%91 |
| logP | -0.8626 |
| TPSA | 441.4 |
| Number of atoms | 57 |
| Number of Hydrogen Bond Acceptors 1 (HBA1) | 23 |
| Number of Hydrogen Bond Acceptors 2 (HBA2) | 26 |
| Number of Hydrogen Bond Donors (HBD) | 7 |
| InChI | |
| InChIKey |
* Chemical properties calculated with Open Babel - O'Boyle et al. Open Babel: An open chemical toolbox. J Cheminform 3, 33 (2011) (link)
QM Data:
| Dipole Magnitude [D]: | 47.902060189 |
| Energy [Eh]: | -3922.23159044052 |
| HOMO [eV]: | -8.7645 |
| LUMO [eV]: | -0.565 |
| Gap [eV]: | 8.1995 |
Download QM Data:
| Charges | charge.txt |
Download Structures
| 2D | .png .mol .mol2 .sdf .pdb .smi |
| 3D | .mol .mol2 .sdf .pdb |
Tautomers
| Tautomers SMILES |
NC(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(N)ncnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)=O tautomer #0
NC(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(N)ncnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)=O tautomer #1 NC(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(N)ncnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)=O tautomer #2 NC(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(N)ncnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)=O tautomer #3 NC(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(=N)nc[nH]c45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)=O tautomer #4 NC(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(=N)[nH]cnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)=O tautomer #5 NC(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(=N)nc[nH]c45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)=O tautomer #6 NC(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(=N)[nH]cnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)=O tautomer #7 N=C(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(N)ncnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)O tautomer #8 N=C(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(N)ncnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)O tautomer #9 N=C(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(N)ncnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)O tautomer #10 N=C(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(N)ncnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)O tautomer #11 NC(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(N4C=NC5C(=N)N=CN=C45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)=O tautomer #12 NC(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(N4C=NC5C(=N)N=CN=C45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)=O tautomer #13 N=C(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(=N)nc[nH]c45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)O tautomer #14 N=C(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(=N)[nH]cnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)O tautomer #15 N=C(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(=N)nc[nH]c45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)O tautomer #16 N=C(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(n4cnc5c(=N)[nH]cnc45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)O tautomer #17 N=C(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(N4C=NC5C(=N)N=CN=C45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)O tautomer #18 N=C(c1ccc[n+](C2OC(COP([O-])(OP([O-])(OCC3OC(N4C=NC5C(=N)N=CN=C45)C(O)C3OP([O-])(OCC6OC(C(O)C6O)*)=O)=O)=O)C(O)C2O)c1)O tautomer #19 |
| Tautomer image | Show Image |
{kind=link}
Predicted CYP Metabolic Sites
| CYP3A4 | CYP2D6 | CYP2C9 |
|---|---|---|
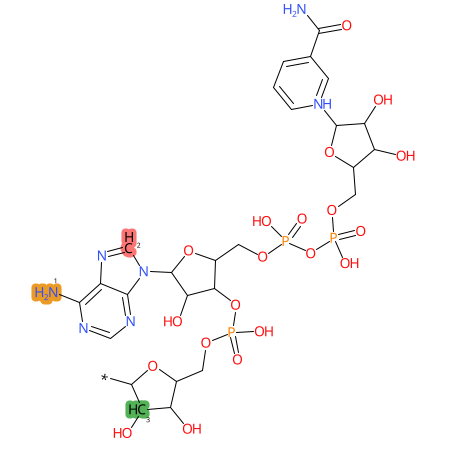
|
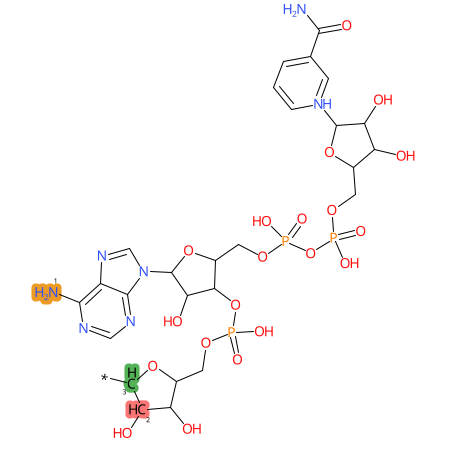
|
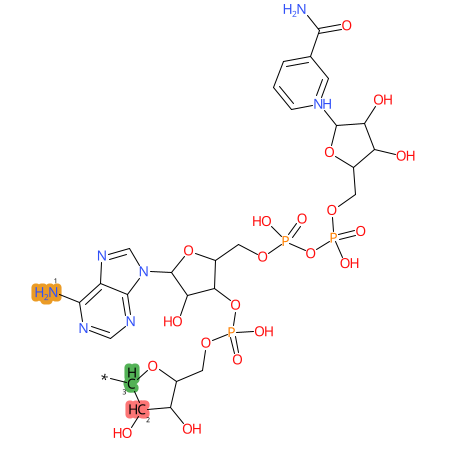
|
* CYP Metabolic sites predicted with SMARTCyp. SMARTCyp is a method for prediction of which sites in a molecule that are most liable to metabolism by Cytochrome P450. It has been shown to be applicable to metabolism by the isoforms 1A2, 2A6, 2B6, 2C8, 2C19, 2E1, and 3A4 (CYP3A4), and specific models for the isoform 2C9 (CYP2C9) and isoform 2D6 (CYP2D6). CYP3A4, CYP2D6, and CYP2C9 are the three of the most important enzymes in drug metabolism since they are involved in the metabolism of more than half of the drugs used today. The three top-ranked atoms are highlighted. See: SmartCYP and SmartCYP - background; Patrik Rydberg, David E. Gloriam, Lars Olsen, The SMARTCyp cytochrome P450 metabolism prediction server, Bioinformatics, Volume 26, Issue 23, 1 December 2010, Pages 2988–2989 (link)
LC-MS Information
| Monoisotopic mass | 661.0935 |
| Average mass | 856.496 |
| [M+H]+ | not available |
| Product ions | not available |
| Normalized LC elution time * | not available |
| LC elution order/characteristics | not available |
* normalized to guanosine (G), measured with a RP C-18 column with acetonitrile/ammonium acetate as mobile phase.
Reactions producing 5' nicotinamide adenine dinucleotide
| Name |
|---|
| pppN:NADpN |
Publications
| Title | Authors | Journal | Details | ||
|---|---|---|---|---|---|
| Giardia lamblia RNA cap guanine-N2 methyltransferase (Tgs2). | Hausmann S, Shuman S | J Biol Chem | [details] | 16046409 | - |
Last modification of this entry: Sept. 15, 2025